
Witness Testimony Highlights the Significance of User Data in Google’s Search Algorithm

On Sept. 20, 2023, during the seventh day of the ongoing antitrust trial United States of America v. Google, LLC, a former Google Software Engineer gave testimony that revealed information about the role that user interaction data plays in Google’s scoring and ranking systems. What I have learned is that it is significant.
The Government’s witness, Dr. Eric Lehman (Theoretical Computer Science, MIT), worked in search quality and ranking at Google for a little over 17 years. When asked to explain to the court what user interaction data is with respect to search quality, Dr. Lehman stated the following.
The biggest problem in search, given a query and a web page, is if the web page is relevant to the query. A person can figure that out pretty easily. They just read the web page and think about it. But a search engine runs on computers, and they couldn’t read.
So there’s sort of a trick to get around that, which is you show web pages to people and then see their reaction, and that can give you some sort of hint about whether or not the web page is relevant to the query.
Dr. Lehman stated that it was fair to say that user interaction data provides feedback from users about their search results, and also confirmed that user interaction events are logged, time-stamped, and recorded.
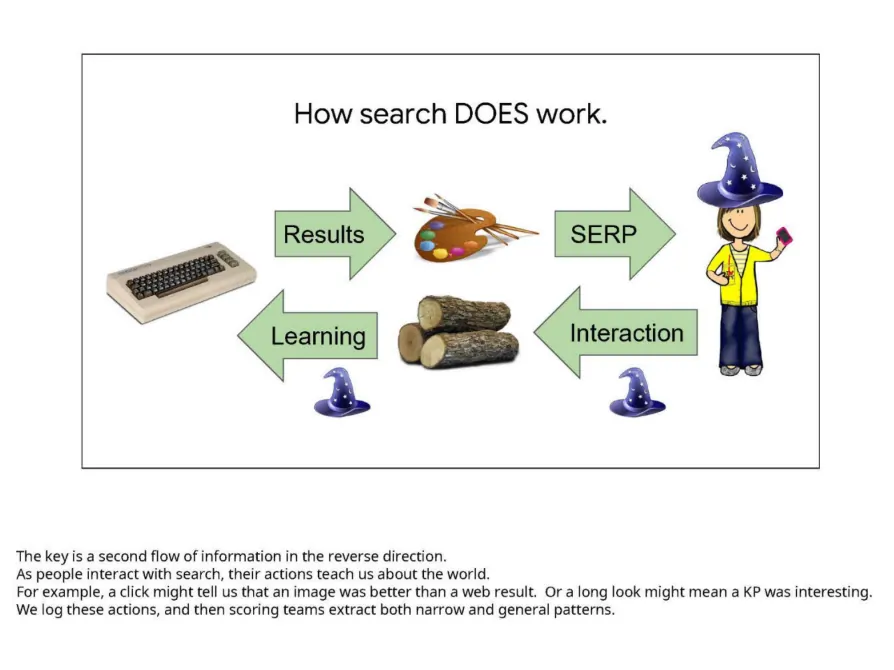
A slide deck titled “Google is magical” (Trial Exhibit – UPX0228), drafted by Dr. Lehman back 2017 shows how user interaction data is used by Google’s ranking algorithm to improve search results. The idea that user data somehow affects ranking is by no means a new theory within the SEO community, but it is nice to hear it confirmed in this context. User interaction data is, for lack of a better term, the icing on the cake for Google’s scoring system.
So for each specific query, there’s a scoring process for all the results, and then results are ranked by decreasing store. And the user data may affect the scoring of those individual results and so affect how they’re ranked.



What Was Happening at Google Search in 2017
According to Dr. Lehman’s sworn testimony, “Google is magic” was drafted in 2017. To me, it reads like a deck that was either presented during a project kickoff or at an all-hands before a big release. One thing is for certain, and it’s that in 2017 Google’s ranking systems were either already learning from user interaction data, or they were going to start soon.
There were four unconfirmed algorithm updates in 2017, two of which were significant enough to have been named by the community.
- “Fred” – March 8, 2017 – Gary Illyes made a joke referring to it as “Fred” which stuck
- “Maccabees” – December 14, 2017 – Named by Barry Schwartz in lieu of Chanukah, and who the Maccabees were.
While Maccabees merely defined by being extreme SERP volatility and fluctuation, the consensus was that Fred had to do with link quality. Perhaps user interaction data was the gas that Google’s ranking systems needed to crack down on link spam in a way it was unable to before.
Google Analytics Data as a Rankings Factor: A Misattribution of Causality
For a long time many in the SEO industry have theorized that Google might use Google Analytics data in it’s rankings algorithm(s). Despite both Matt Cutts and John Mueller having come out on multiple occasions saying that it is not, many SEOs remained skeptical. Matt and John were (and have been) telling the truth. On its face, the idea that Google Analytics, a consumer software product, would ever be the source of any signal used by the company’s internal proprietary algorithm(s) is unrealistic. That doesn’t mean that similar metrics aren’t collected by a internal system that is not a consumer product, and that does in fact affect how search results are ranked.
The most recent piece I can find on the matter was published on October 4th, 2023, by Vahan Petrosyan (SEJ) titled Is Using Google Analytics A Search Ranking Factor?. In it, Vahan offers this screenshot from How Search Works 2022:

Source of the original document is unknown
While the piece does a commendable job of rejecting that it is not Google Analytics data, the idea of what it might be if not is mostly brushed aside. The question still remains, if user interaction data is not Google Analytics data, then what is it?
What is “interaction data,” and where does Google get it?
Some marketers hypothesize that these factors include metrics such as time on page, organic click-through rate, bounce rate, total direct traffic, percentage of repeat visitors, etc.
Dr. Lehman’s testimony and documents submitted to the court as evidence provide us with some answers.
There are Four Categories of User Interactions
- Read Interactions
- Click Interactions
- Scroll Interactions
- Mouse Hover Interactions
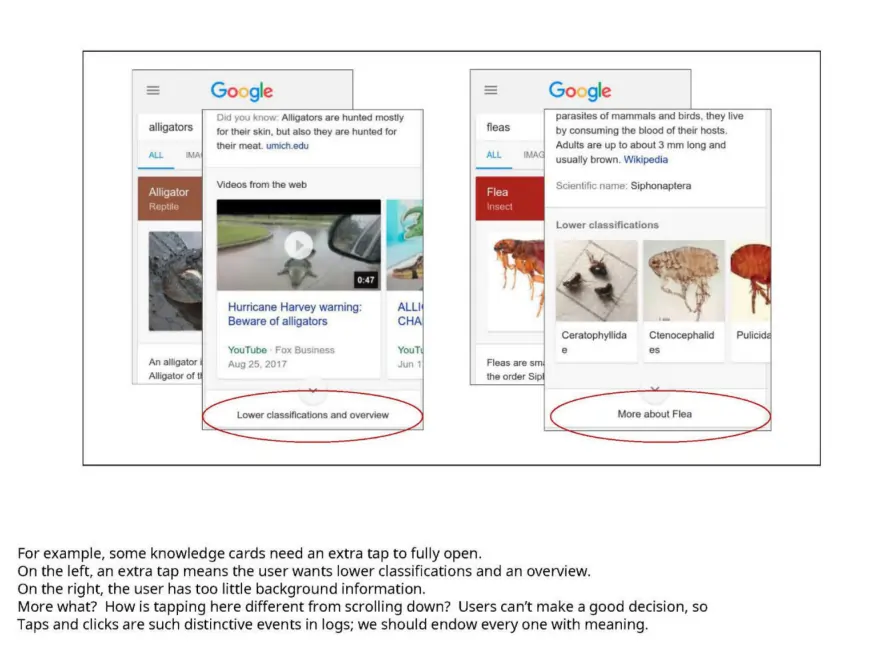
In the courtroom they were looking at an exhibit of a slide that included these categories. Lehman was uncertain wether the first category was “read” as in “I read the book” or as in “I read for fun”, but said that it basically tracks where a user’s attention is.
As along as they’re on Google, I mean, as long as they’re looking at a Google web page, then we have a chance to sort of see what are they doing, we can see are they looking at the top of the page or the bottom or something like that.
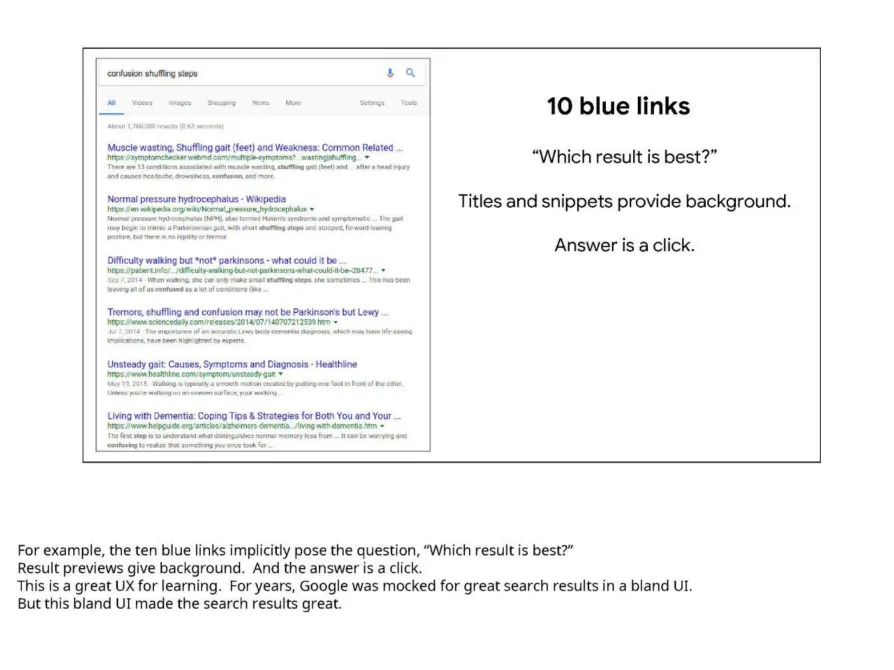
Metrics derived from user interaction data are treated as relevancy signals, which in turn may have an impact on how Google’s algorithm(s) decide to rank search results. Click duration is one of those metrics. Dr. Lehman stated that there is a correlation between click duration and ranking, but it is weak. Click duration measures the time between when a user clicks on a result and when they come back to a SERP. Based on that time, a click is determined to be a short click or a long click.
Precise definitions have varied a lot over the years, but a short click would typically be one where somebody clicks on a search result and then comes back to Google fairly soon after.
Lehman revealed that the concept of “tabbed browsing” can make things complicated. Tabbed browsing is when a user clicks on several promising results and then go through each one by one (and is very common). In addition, media type can also create complications, for example with video, a user might be gone for several minutes before they come back to the search results.
So the click duration, it’s a pretty noisy signal, but I think in general the thinking is long clicks are typically better than short clicks.
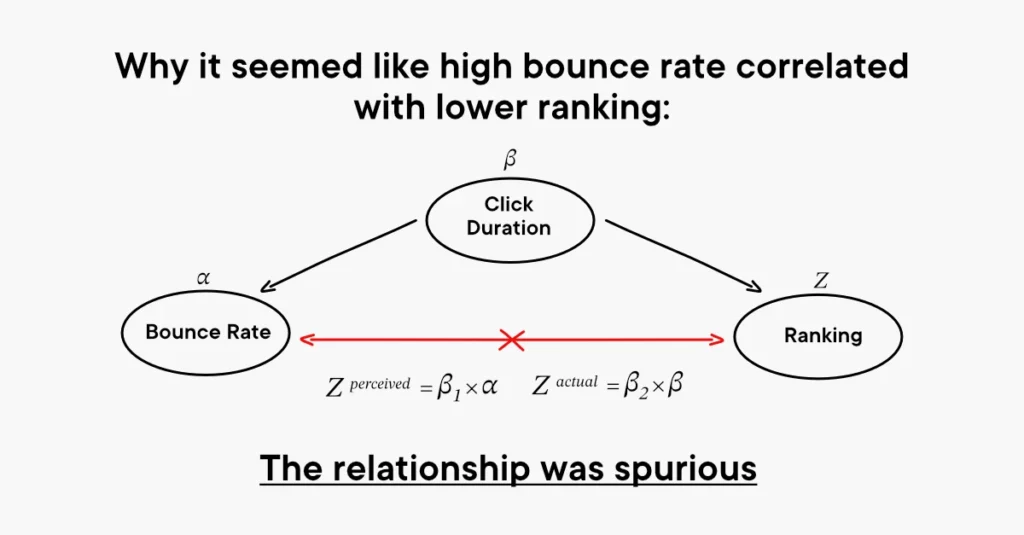
The reason that many SEOs believed that Google Analytics data was a rankings factor was because they saw correlations between GA metrics and changes in their sites’ ranking. In reality, these correlations were likely spurious. In the context of experimental hypothesis testing, a spurious relationship is when two or more events or variables are associated but not causally related, due to either coincidence or the presence of a certain third, unseen factor. My theory is that the underlying suspicions of many SEOs weren’t “wrong”, they just incorrectly identified the cause. For example, a high bounce rate and a short click duration tell the same story. The same would go for a long click duration and high average engagement time (GA4) or Time on Page (UA).
Measuring Search Quality: Information Satisfaction (IS) and the Live Experiment (LE) Process
At the time that Dr. Lehman left Google, the primary measure of search quality was IS4 (information satisfaction version 4). Information Satisfaction is a human-rater based evaluation. My assumption here is that this metric is derived from how Google’s Search Quality Evaluators (whom Google publicly issues guidelines for) rate results.
the IS metric is the best metric we have for measuring the quality of search results, but in certain — there are aspects of the quality of search results that it doesn’t capture
Other metrics are derived from Learning Experiments (LE), which we know occur because Google is open to the public about the fact that they conduct them. In the SEO community we often observe high SERP volatility or strange things occurring outside of a confirmed algorithm update. Live experiments could be at least one reason why.

Search Quality Rater Guidelines: An Overview (Slide 13)
One challenge is that IS and LE sometimes disagree. While Information Satisfaction (IS) is the best available single metric Google has for measuring the quality of search results, but there are some aspects of quality that it doesn’t answer.
Google Re-writing / Ignoring Title Tags
Back in 2021 Google made announcement that more than just an html title would be used to generate page titles in search results. This became a hot topic in the SEO community and was highly controversial.
The publicly facing reason for doing so was to produce more readable and accessible titles for pages. I don’t disagree that there was a problem with page titles. Title tags that followed the Keyword | Keyword | Keyword model did ultimately say a lot more about the keywords that site owners wanted to rank for than accurately describe what the page was about.

But if not solely to improve the readability and accessibility for users, then what? A slide introduced to the court titled “Result Previews and Language Understanding” along with Dr. Lehman’s testimony offers a logical reason.

So better result previews has two benefits. One is happy users. We’re not sending people off on useless web pages. And it has a second benefit, which is more informed user interactions. If people know what they’re clicking on, then the clicks become more meaningful.
As an extreme, you could imagine if we had a search result page and we just said here are results 1 through 10 and gave you no information, your clicks would be random and meaningless.
So by improving result previews, clicks contain more information. So it isn’t the happy users that give better training data. It’s the second bullet point, more informed user interactions.
Controlling the page titles that appeared on SERPs meant that clicks would carry more meaning, and in turn improve Google’s language models.
Unified Click Prediction: Reading Between The Lines of IS & LE
The reason that Google has been the default search engine for so long is because it offers the best results. Period. While user data has played a pivotal role in the company’s ability to deliver “magic” there is nothing magical about user data. It has been the company’s ability to take advantage of it has set them apart.
At one point in court during the testimony Murdock-Pack directed Lehman’s attention to a deck submitted as evidence titled “unified click prediction”. The first two slides of the deck prove a lot.


Further questioning revolved around two slides: the first titled “approximately 1 million IS ratings”, and the second titled “approximately 100 billion clicks”.
A behavior pattern apparent in just a few IS ratings may be reflected in hundreds of thousands of clicks, allowing us to learn second and third order effects
The moral of the story is that Google’s overall goal is to get better at understanding language and the world through the data collected through IS and LE.
Learning from logs is the main mechanism behind ranking. Not one system but a great many within ranking are built on logs.
Every part of Google Search involves user data. Some components take it directly, and others indirectly. Much of the user data collected while we’re searching fuels completely different sides of Google as well, such as YouTube, Play. It wasn’t mentioned explicitly in the testimony one can assume that Maps is probably another.
There are components in Search which make use of user data, and then there are cases where we will take, say, take data from that first system and sort of reprocess it and use it in another way
To What Extent are Google’s Ranking Systems Still Relying on User Data?
With the advancements of BERT begs the question of how important user interaction data is to Google’s ranking algorithm(s).
In one direction, it’s better to have more user data. At the same time, with technology improvement, later systems in some cases require much, much less user data.
At the time that Google is magic was written, Dr. Lehman considered user interaction data to be the most effective way that Google learns. However, in his testimony admitted that the situation is changing rapidly. Later in his testimony, Dr. Lehman admitted that until 2020 it was true that both older Google ranking systems and new machine learning systems used user data, however, since then an important machine learning system did not use any. In 2020, I can only assume this was BERT. A year later we saw Google roll out its Multitask Unified Model, or MUM, which is also a machine learning algorithm, so I’d assume that it did not use any either.
Google’s Public vs. Private Stance on the Role of User Data in Search
Google has purposely kept it’s use of user data under wraps. If the SEO community, especially black hats, had really known about this, of course people would try to take advantage of it. It’s likely that many probably have, but Google’s unambiguous messaging kept it curtailed. However, the fact that Dr. Lehman is giving this testimony, I assume that Google is either now able to catch efforts to manipulate results, or due to the advancements in machine learning, is not using it as much anymore.
I think the position that we’ve strived for is…to try not to give them a really clear and unambiguous message that we use user data, because they could potentially manipulate it to damage Google and damage the quality of search results for everyone who uses Google. So we have said that we use user feedback data, clicks, in evaluation of our search systems. And we try to avoid confirming that we use user data in the ranking of search results. So this has included things, I think, like saying well, there are a lot of challenges with using clicks in ranking of search results, not outright saying we don’t do it but not encouraging the belief that we do.
Transcript
Below is a link to my copy of the transcript that I’ve referenced throughout this article. Many relevant sections are highlighted for ease of finding things. I encourage a full read. There’s quite a bit that is redacted towards the end.