
Why Structured Data is Important for Semantic SEO

Over the past decade, search engines have been increasingly using structured data to interpret what is on our web pages.
Getting familiar with structured data will greatly benefit website owners as well as beginner and intermediate SEOs.
Experienced Webmasters and SEOs can benefit from advanced methods of customizing structured data that can be used to strengthen the semantics we convey to search engines.
The Semantic Web & Semantic SEO
The “Semantic Web” refers to the world of real objects on the internet, not just web documents. Real-world objects are the sort of data you find in databases, such as Wikipedia.
It assigns URIs (Uniform Resource Identifiers) to many things – web pages, people, cars, and even abstract ideas.
“Semantic Web” is also W3C’s (World Wide Web Consortium) vision of the Web of linked data. The purpose of the Semantic Web is to preserve a shared understanding about what a URI identifies.
In 2008, Cool URIs for the Semantic Web cited the following two main requirements for how real-world objects or things should be identified on the web:
- A URI should provide information about what it identifies in a machine-readable (e.g. Resource Description Framework or “RDF”) and human-readable (e.g. Hyper Text Markup Language or “HTML”) format.
- There should be no confusion between identifiers for Web documents and identifiers for other resources. URIs are meant to identify only one of them, so one URI can’t stand for both a Web document and a real-world object.
Remember that second requirement because we’ll come back to it.
The easiest way to understand semantic search is to think of it as searching by meaning. It allows for more accurate information retrieval and also helps provide answers to questions that may not be easily found through typical keyword searches.
This means that websites can be found and ranked based on their relevance to specific phrases or subject matter, and not just based on keywords alone.
The use of the term semantic search is not very consistent, but this is largely because of how fast new techniques to understand meaning have evolved over the past decade.
Google’s Timeline: The semantic evolution happened fast
2012 – Google Knowledge Graph & things, not strings
2013 – Conversational search
2015 – RankBrain – an artificial intelligence (AI) system used by Google to understand search intent
2019 – BERT (Bidirectional Encoder Representations from Transformers) is a revolutionary method for natural language processing (NLP) pre-training developed by Google.
Structured Data: A Method to Convey Meaning
Broadly, structured data refers to any data that is organized in a predefined format or schema, making it easily searchable and identifiable by algorithms and database systems. It provides a standard way to share information about content, so that a computer can understand it and present it in meaningful ways (eg., the author of a news article or a blog).
On the web, structured data can be used to annotate (or “mark up”) content, making it easier for search engines to understand the context of the information on web pages.
This is achieved through the use of formats such as JSON-LD, Microdata, and RDFa, which allow SEOs and Marketers to specify information about the page content, such as products, recipes, reviews, and events, in a way that can be directly processed by search engines to improve search results and enable rich snippets in search listings.
As you may know or already gathered, Structured Data enables search engines to more accurately serve results that match a user’s query. Adding it to your website can improve its relevance for certain queries.
In summary, structured data is instrumental in realizing the vision of the Semantic Web by providing a means to explicitly define, link, and share data in a semantically rich and machine-understandable format.
This not only facilitates better data integration and collaboration across the web but also paves the way for more intelligent and adaptive web services and applications.
Schema.org: The Semantic Markup for SEO
With the advancements in cognitive computing and machine learning that took place around the 2005-2010 period, there came an increasing need for a structured data format that computers could easily understand.
To meet this demand, in 2011 the Schema.org initiative was created by search engine companies (including Google) and large-scale web publishers who wanted to describe objects on pages so they could be better understood by machines.
Schema.org provides a framework that helps you describe what your content means and how it is related to other things on your website. At a minimum, schema will help search engines more accurately index your content.
Assuming your content is also good, implementing structured data may help some of your pages rank higher in organic results.
If structured data is like speech, schema.org is like a dialect of the language being spoken. Specifically, schema.org is a Schema Vocabulary. It is the primary vocabulary we use in structured data for SEO.
JSON-LD (JavaScript Object Notation for Linking Data)
JSON-LD was only recently (2015ish) adopted as the standard amongst popular search engines, but it’s been gaining traction for almost a decade now. In 2015 Google began supporting the format, and as of 2017 officially recommend using it for structured data.
On the left is a bar graph showing the global usage statistics of structured data formats. Currently, only 38% of sites are using JSON-LD.
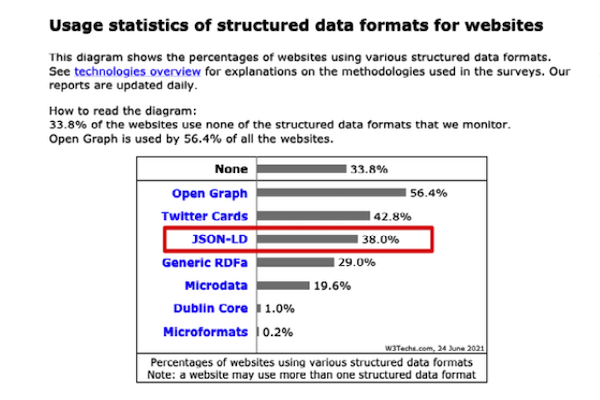
When someone that identifies as an SEO broadly mentions structured data, they probably mean JSON-LD written in the schema.org vocabulary.
Technically speaking, the XML in your Sitemap.xml file is also structured data. We just don’t commonly associate it with structured data in the same sort of way as we do with JSON-LD.
The point to understand here is that structured data is not just a thing SEOs use to generate SERP features and rich snippets.

Semantic SEO: Providing Google with More Context
Semantic SEO focuses on the intent and meaning behind user queries rather than just concentrating on incorporating specific keywords. It involves understanding how search engines use semantic search principles to interpret and deliver results that meet the searchers intent as accurately as possible.
We can use structured data to help search engines understand the context and relationships between elements on a page. What’s important to call out here is that most of these benefits fall inside the realm of what’s called Theoretical SEO. Writing structured data for semantics is not something you would normally sell your clients on, but it is something you might do on your test sites.
None of this is to say that Semantic SEO is not real. It’s just not something that we can typically tie to ROI. There are definitely exceptions to this though as case studies supporting strategies such as topical authority are beginning to emerge. The first point I want to talk about is using Semantics to enhance content understanding and more accurate indexing.
Through semantics we can provide additional information in our structured data about our content that semantic search engines are capable of understanding, regardless if its part of what Google requires for a rich snippet. The idea is that this in turn, will help Google more accurately index our content on improved data connectivity, you can think of this in the same way that you would with your internal linking strategy except you’re doing it with structured data instead of anchor text and providing much richer information.
The next thing we can do is facilitate the creation of knowledge graphs. Here the goal is to provide data about entities that exist in Google’s knowledge graph, in a structured format, so that the graph can consume it. This can establish trust signals, however, it requires a lot of authority.
The primary benefactor here is the knowledge graph. So in this sense, we’re giving it information.
The next way we can use structured data for semantic optimization is by what I call “piggybacking” off of knowledge graphs. Essentially what we’re doing is pointing to an entity in our content and telling search engines that it’s the same thing as what for example, a Wikipedia page represents. It’s a powerful tool to help search engines understand our content, which we’ll discuss more later on.
Another aspect of semantic SEO we can optimize with structured data is supporting voice search and virtual assistants. I think we will see a rise into voice searches already quite strategic, especially for local SEO. However, with generative AI and virtual assistants on the rise, we may see this happen more quickly.
For this we can use the Speakable and speakableSpecification.
Quick Tips for Semantic Optimization
- Keyword Mapping
- Find co-occurring terms, variants, think of other ways the thing is referred to
- Include core keywords in: title tags, h1s, URL slugs, etc
- Include co-occurring/variants in: body content, meta descriptions, alt text, anywhere else that makes sense
- Research methods: Live search results, competitor analysis tools, Ahrefs Content Explorer, keyword research tools, custom scrapers, and more.
- Other research methods: Surveys, Interviews
- Phrase Mapping & Theme Modeling
- Look at pages that rank on the first page for a given search, identify unique phrases that appear in close proximity multiple times
- Be specific: “The former president”, “Former US President, Barack Obama”
- Avoid Idioms and other figurative/non-literal words
- Include in: H1-H6, body content, anchor text, alt text, captions, anywhere else that makes sense
- Research methods: People also ask, auto complete, keyword research tools (Ubersuggest is free), Answer the Public, Wikipedia, DBpedia, and more
- Remember the 5 W’s – Who, What, Where, When, Why
- Who/what: Name of the thing (Ex MozCon)
- What: Primary function, usage, purpose, etc (SEO Conference)
- Where: Where it’s relevant (Seattle)
- Who/when: When and to whom is it relevant (marketing professionals, in the summer)
Writing Custom Structured Data for Semantics
Schema.org is very expansive. There are all sorts of ways we can customize our structured data beyond the scope of Google’s SERP feature gallery. As we’ve discussed so far, the more semantics we can create, the better. Being diligent about marking up as much of your content as possible is a great way to get a leg up over your competitors.
To enhance the clarity and utility of your section on “Representing Multiple Types of Things on a Page” with the goal of teaching the power of nesting JSON-LD, when to use separate objects, and representing multiple types of Schema.org types on a page, I’ve expanded each part with more helpful and high-quality information.
Representing Multiple Entities and Types on a Page
When crafting structured data for a webpage, you might encounter situations where multiple items or entities need to be described simultaneously. The decision on whether to “nest” these items within each other or to list them as separate entities depends on their relationship and the context in which they are presented. Understanding when and how to use each approach can significantly enhance the effectiveness of your structured data.
Using Separate Objects
Definition: Listing separate objects involves creating distinct blocks of JSON-LD for each item or entity on your page that stands alone or does not have a direct hierarchical relationship with other items.
When to Use:
- Distinct Entities: Use separate objects for items that function independently on the page, such as breadcrumbs, images, videos, FAQs, and reviews.
- Enhanced Clarity: Separating items into individual blocks can improve the readability of your structured data, making it easier for search engines to understand and index each element accurately.
- Modular Updates: When items might be updated independently of each other, maintaining them as separate objects simplifies content management and updates.
Example: A webpage with an article, a video tutorial, and user reviews would benefit from separate JSON-LD blocks for each component to clearly delineate their distinct nature and content.
The Power of Nesting
Nesting involves embedding objects within other objects to create a hierarchical structure. This approach is used to indicate relationships between entities, such as parent-child or container-contained relationships.
When to Use:
- Related Entities: Nesting is ideal for representing entities that have a direct relationship with one another. For example, an article entity might contain nested author and comment entities, indicating the author of the article and comments related to it.
- Complex Data Structures: Use nesting to convey complex data relationships, such as products within a specific category, services offered by an organization, or episodes within a TV series.
- Efficient Data Grouping: Nesting allows for the efficient grouping of related information, reducing redundancy and improving the coherence of the structured data.
Example: An event page could use nesting to include the event’s location (Place) entity within the event (Event) entity, seamlessly linking the venue’s details with the event information.
Best Practices
- Consistency: Maintain consistency in how you use nesting and separate objects across your site to aid in the predictable organization and interpretation of your structured data.
- Testing: Utilize tools like Google’s Structured Data Testing Tool to validate your JSON-LD markup, ensuring that it accurately reflects the intended structure and relationships.
- Documentation: Document your structured data approach, especially the logic behind nesting and separating objects, to facilitate maintenance and future development.
Creating a Custom Organization Schema
Here’s organization script that references the entity “Example Software Company” while including a SoftwareApplication schema.
In this example, we’re informing search engines about a tech company that makes a software application called “SalesFarce CRM”. On average, the app has a rating of 2.6/5 stars.
What is interesting is that we’re also informing search engines that a company called “B2B Software Sales” is a seller of the product, despite it being free.
These semantics might be incredibly important, because now if the seller publishes content about the company, search engines can better understand their relationship.
// Identifies an entity as a 3rd party seller of software
{
"@context": "https://schema.org",
"@type": "Organization",
"name": "Example Software Company",
"url": "https://example.com/",
"logo": "https://picsum.photos/200",
"hasOfferCatalog": {
"@type": "OfferCatalog",
"name": "Software as a service",
"alternateName": "SaaS",
"itemListElement": [
{
"@type": "Offer",
"itemOffered": {
"@type": "SoftwareApplication",
"name": "SalesFarce CRM",
"operatingSystem": "All",
"applicationCategory": "WebApplication",
"aggregateRating": {
"@type": "AggregateRating",
"ratingValue": "2.6",
"ratingCount": "8864"
},
"offers": {
"@type": "Offer",
"price": "1.00",
"priceCurrency": "USD"
}
}
}
]
},
"seller": {
"@type": "Organization",
"name": "B2B Software Sales Company",
"url": "https://www.example-software-global.net/",
"logo": "https://picsum.photos/200L"
},
"sameAs": [
"https://twitter.com/example-software-company",
"https://linkedin.com/example-software-company",
"https://facebook.com/example-software-company"
]
}
We can see the Rich Result Test checks out just fine.
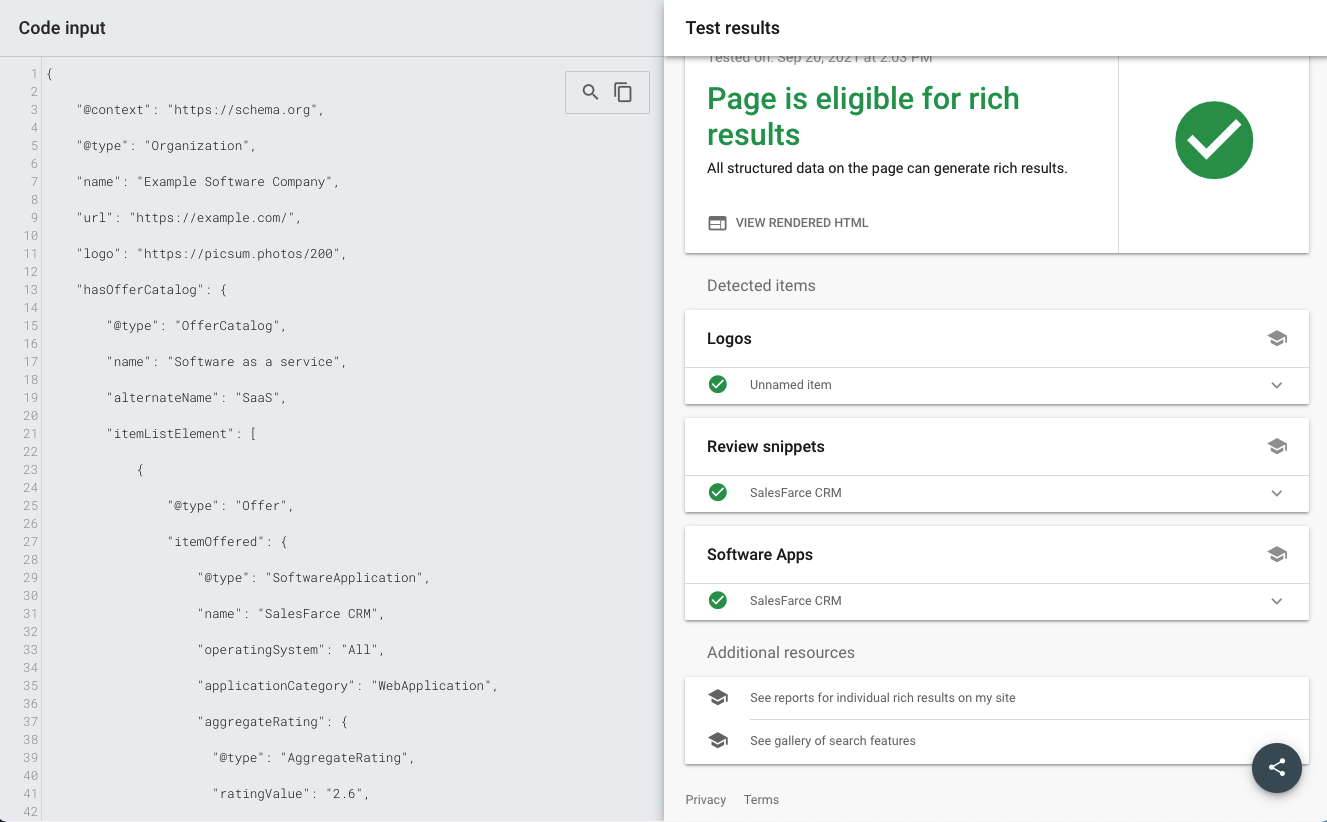
Testing Variations: Custom Organization Schema
The schema below contains a custom organization schema that I’ve been testing on agency’s website. It’s designed to tell search engines about our location, the areas we serve, as well as our core services. It passes both Google’s Rich Results test and the Schema Markup Validator (Beta)
{
"@context": "https://schema.org",
"@type": "Organization",
"name": "Ciffone Digital",
"legalName": "Ciffone Digital, LLC",
"slogan": "Disrupt the Status Quo",
"founder": "Mike Ciffone",
"url": "https://ciffonedigital.com",
"logo": "https://ciffonedigital.com/wp-content/uploads/2021/03/Ciffone-Digital-Logo-Primary-CD.png",
"email": "[email protected]",
"telephone": "(312) 508-3012",
"areaServed": ["US","GB","CA"],
"availableLanguage": [
{
"@type": "Language",
"name": "English"
}
],
"location": {
"@type": "Place",
"address": {
"@type": "PostalAddress",
"addressLocality": "Chicago",
"addressRegion": "IL",
"postalCode": "60610"
}
},
"hasOfferCatalog": {
"@type": "OfferCatalog",
"name": "Digital Marketing services",
"itemListElement": [
{
"@type": "Offer",
"itemOffered": {
"@type": "Service",
"name": "Search Engine Optimization",
"alternateName": "SEO"
}
},
{
"@type": "Offer",
"itemOffered": {
"@type": "Service",
"name": "Content Marketing"
}
},
{
"@type": "Offer",
"itemOffered": {
"@type": "Service",
"name": "Website Development"
}
},
{
"@type": "Offer",
"itemOffered": {
"@type": "Service",
"name": "Pay-Per-Click",
"alternateName": "PPC"
}
}
]
},
"sameAs": [
"https://ciffonedigital.com",
"https://github.com/Ciffone-Digital",
"https://www.linkedin.com/company/ciffone-digital/",
"https://twitter.com/ciffone_digital",
"https://www.facebook.com/ciffonedigital"
]
}
Grouped Offers with ItemList for Price Drops and Seasonal Promotions
Here’s an eCommerce example. This custom schema.org markup employs an ItemList to group multiple offers for a single product or service on our website. This approach is designed to semantically enrich the presentation of special offers, such as price drops and seasonal promotions, providing our visitors with clear, structured information that highlights the value and temporal nature of each promotion.
Key features:
- Structured Collection of Offers: By grouping offers under an
ItemList, we create a semantically structured collection that implies a relationship between the offers. This indicates to our visitors that these are not just random promotions but are related offers, providing options like different pricing tiers or conditions for the same product. - Semantic Highlighting of Promotions: Each offer within the
ItemListis named descriptively (e.g., “Spring Sale” for discounted offers and “Regular Price” for standard pricing), directly communicating the nature and value of the promotion. This clarity helps visitors understand the special conditions, such as limited-time availability or seasonal relevance.
{
"@context": "https://schema.org/",
"@type": "Product",
"name": "Men's Raincoat",
"url": "https://example.com/products/raincoat",
"image": [
"https://example.com/photos/1x1/photo.jpg",
"https://example.com/photos/4x3/photo.jpg",
"https://example.com/photos/16x9/photo.jpg"
],
"description": "Waterproof Mens raincoat perfect for spring",
"sku": "0446310786",
"mpn": "925872",
"brand": {
"@type": "Brand",
"name": "Example Nature Outdoors",
"id": "wikipedia.com/wiki/example-nature-outdoors",
"url": "example-nature-outdoors.com"
},
"review": {
"@type": "Review",
"reviewRating": {
"@type": "Rating",
"ratingValue": 4,
"bestRating": 5
},
"author": {
"@type": "Person",
"knowsAbout": "Hiking and the outdoors",
"name": "Jane Doe",
"sameAs": "https://instagram.com/jane-doe-outdoors"
},
"aggregateRating": {
"@type": "AggregateRating",
"ratingValue": 4.4,
"reviewCount": 189
},
"positiveNotes": {
"@type": "ItemList",
"itemListElement": [
{ "@type": "ListItem", "position": 1, "name": "Very waterproof" },
{ "@type": "ListItem", "position": 2, "name": "Extremely durable" }
]
},
"negativeNotes": {
"@type": "ItemList",
"itemListElement": [
{ "@type": "ListItem", "position": 1, "name": "Limited colors available" }
]
}
},
"offers":{
"@type": "itemList",
"itemListElement": [
{
"@type": "offer",
"name": "Spring Sale",
"priceSpecification": {
"@type": "PriceSpecification",
"price": 80.99,
"priceCurrency": "USD"
},
"priceValidUntil": "2024-6-20",
"itemCondition": "https://schema.org/NewCondition",
"availability": "https://schema.org/InStock"
},
{
"@type": "offer",
"name": "Regular Price",
"priceSpecification": {
"@type": "PriceSpecification",
"price": 160.99,
"priceCurrency": "USD"
},
"itemCondition": "https://schema.org/NewCondition",
"availability": "https://schema.org/InStock"
}
]
},
"hasMerchantReturnPolicy": {
"@type": "MerchantReturnPolicy",
"applicableCountry": "US",
"returnPolicyCategory": "https://schema.org/MerchantReturnFiniteReturnWindow",
"merchantReturnDays": 30,
"returnMethod": "https://schema.org/ReturnByMail",
"returnFees": "https://schema.org/FreeReturn"
}
}
Reasons to Use Both JSON-LD and Microdata
Search engines can have trouble distinguishing the difference in how JSON-LD structured data is written as opposed to textual information on a webpage. The confusion occurs because objects in the document <head> could be very far from the semantic content on the page. This can make verifying the information on Web pages more difficult. Especially for less seen schema types/properties/classes.
One pro of using microdata is that since the code is integrated in the HTML, it appears very close to the actual information it is referencing. This can potentially make search engines more confident in the relationship thanks to values being directly associated with texts on a web page.
Alternatively, Schema.org provides WebPageElement, which accepts the following properties cssSelector or xpath.
| Properties from WebPageElement | ||
|---|---|---|
| cssSelector | CssSelectorType | A CSS selector, e.g. of a SpeakableSpecification or WebPageElement. In the latter case, multiple matches within a page can constitute a single conceptual “Web page element”. |
| xpath | XPathType | An XPath, e.g. of a SpeakableSpecification or WebPageElement. In the latter case, multiple matches within a page can constitute a single conceptual “Web page element”. |
There are also a handful of more specific types for WebPageElement.